

2. 技术瓶颈:RepFlow-CFR作为深度反事实推理模型,虽能估计个体化治疗效应(ITE)并识别有益治疗路径,但存在"黑箱"问题,决策过程缺乏透明度,且未内置临床指南约束,导致推荐可能与循证实践脱节。
一项利用大语言模型驱动指南依从性以增强呼吸支持预测建模的混合AI研究
期刊:Critical Care
分区:中科院一区
影响因子:9.3
研究背景
1. 临床问题:急性呼吸衰竭(ARF)在ICU中常见,高流量鼻导管氧疗(HFNC)与无创通气(NIV)是首选呼吸支持手段,但两者适应证高度重叠,现有随机对照试验无法覆盖真实世界中的复杂异质性患者群体,缺乏个体化选择依据。
2. 技术瓶颈:RepFlow-CFR作为深度反事实推理模型,虽能估计个体化治疗效应(ITE)并识别有益治疗路径,但存在"黑箱"问题,决策过程缺乏透明度,且未内置临床指南约束,导致推荐可能与循证实践脱节。
3. 证据缺口:传统预测模型仅关注已在接受HFNC患者的失败风险,而非初始 modality 选择;现有因果推断工具虽多样(Causal Forests、TARNet、X-learner等),但均未实现指南对齐与可解释性的有机整合。
4. 研究动机:引入大语言模型(LLM)作为"指南感知层",通过解析结构化患者数据、临床笔记及正式指南标准,对模型推荐进行校验、修正与解释生成,从而提升临床一致性、可解释性与安全性,填补数据驱动与知识驱动之间的鸿沟。
研究设计和参与者
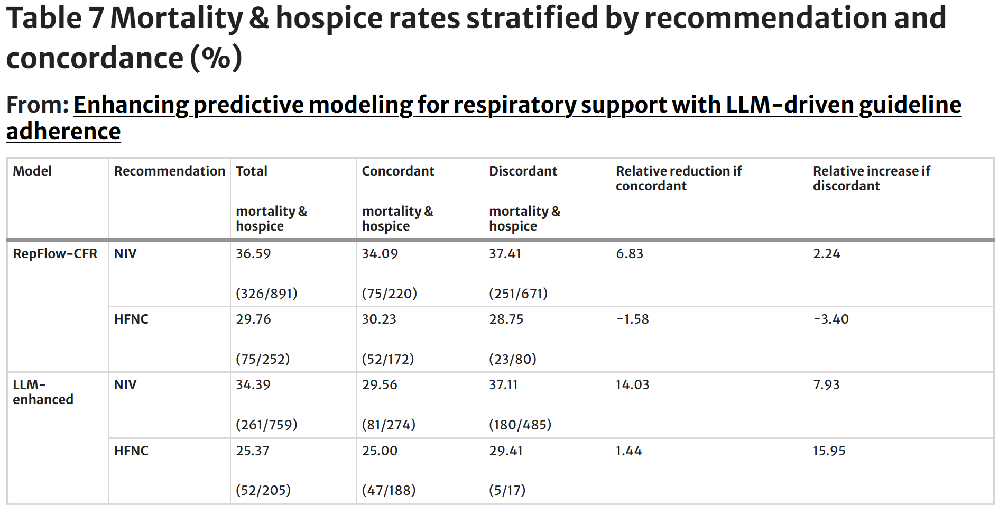
本研究为一项回顾性队列研究,纳入2016年1月1日至2023年12月31日期间UC San Diego Health系统ICU的连续患者。研究从31,180例ICU入院中筛选出5,685例Vent.io模型预测的高危呼吸衰竭患者,最终1,261例接受HFNC或NIV作为首个呼吸支持的成人患者进入主要分析。符合纳入标准者需提供完整的生命体征、实验室、合并症(Charlson指数)及临床笔记数据;排除标准包括:IMV启动前已插管、关键变量缺失、术后24小时内启动治疗者。研究经UCSD伦理委员会批准(IRB#800258),使用去标识化EHR数据。
模型构建与检测流程
研究采用三阶段混合框架:
1. RepFlow-CFR模型:为深度反事实表示学习框架,包含:Stage 0使用反事实回归平衡观测混杂因素;Stage 1采用条件正态流(CNF)建模结局分布;Stage 2引入第二层CNF校正未测量混杂,最终输出个体化IMV风险预测与初步治疗推荐(NIV/HFNC/Indifferent)。
2. LLM整合层:部署于HIPAA-compliant AWS环境,采用Claude 3.5 Sonnet(temperature=0.1)。输入包括:①ERS/ATS 2017 NIV指南与ERS 2022 HFNC指南的结构化指征/禁忌证;②Vent.io T0时间戳;③RepFlow-CFR初步推荐及Top-50 SHAP特征;④T0前最新pH、PaCO₂、呼吸频率、SpO₂、FiO₂;⑤72小时内临床笔记(ED记录、病程、影像报告)。输出为结构化JSON,包含NIV/HFNC推荐、置信度、指南依据及模型一致性判断。
3. 一致性评估:建立两级一致性定义:①RepFlow-CFR Concordance(模型推荐vs实际治疗);②LLM-enhanced Concordance(LLM修正后推荐vs实际治疗)。主要比较一致组与不一致组的IMV率及死亡率/临终关怀率。
测量和主要结果
主要终点:是否需要侵入性机械通气(IMV)(Vent.io T0至插管或出院)。
次要终点:住院死亡率或出院至临终关怀的复合结局。
探索性终点:治疗一致性与结局的关联强度(OR)、相对风险变化、图表审查的指南符合度与临床合理性。
主要的统计学方法
- 描述性统计:连续变量用均值(SD)或中位数(IQR),分类变量用n(%),组间差异用Kruskal-Wallis检验或χ²检验。
- 一致性分析:计算一致组/不一致组的IMV率与死亡率,量化相对减少与相对增加百分比。
- 多变量校正:采用混合效应逻辑回归,控制年龄、性别、Charlson合并症指数、SOFA评分、Vent.io风险评分,计算调整OR及95% CI。
- 图表审查:20例purposive sampling,3名副高以上ICU医师独立评估推荐合理性、解释准确性及潜在危害(采用AHRQ伤害分类框架)。
- 模型性能:RepFlow-CFR在验证集AUC=0.820,PR-AUC=0.566。
研究结果
Figure 1. 研究队列筛选流程
从31,180例ICU入院中,经Vent.io高风险筛选、排除IMV前置及数据缺失,最终1,261例纳入早期HFNC/NIV分析队列,确保研究对象均真实反映初始呼吸支持决策场景。
Figure 2. 患者基线特征与模型推荐分布
RepFlow-CFR推荐891例NIV、252例HFNC、118例Indifferent;LLM-enhanced重新分配为759、205、297例。基线特征(年龄62±16岁,男性58%,SOFA中位数1-2分)在推荐组间保持平衡(p>0.05),证实随机化效应良好。LLM模型使HFNC一致率从68.3%提升至91.7%(p<0.001),显著改善临床-推荐对齐度。
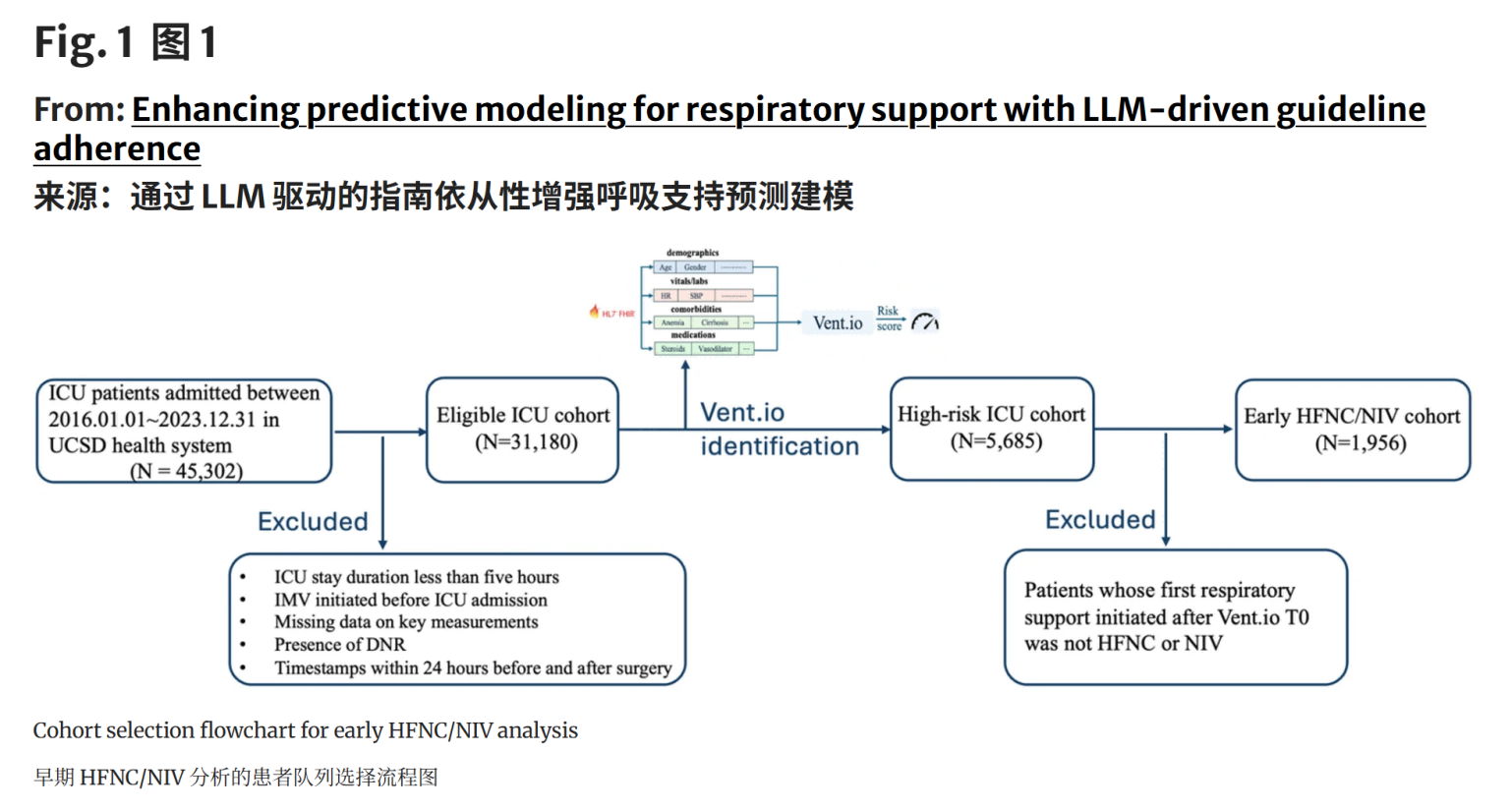
Figure 3. 治疗一致性与患者结局关联
表6/7核心数据:
- IMV结局:LLM-enhanced框架下,HFNC推荐组中,一致组IMV率24.47%,不一致组骤升至52.94%,相对风险增加97.33%;NIV一致组IMV率21.17%,不一致组28.65%(相对减少8.80%)。
- 死亡/临终结局:NIV一致组相对风险降低14.03%,显著优于基线模型的6.83%(LLM-enhanced OR=0.67, 95% CI: 0.45-0.99, p=0.046)。

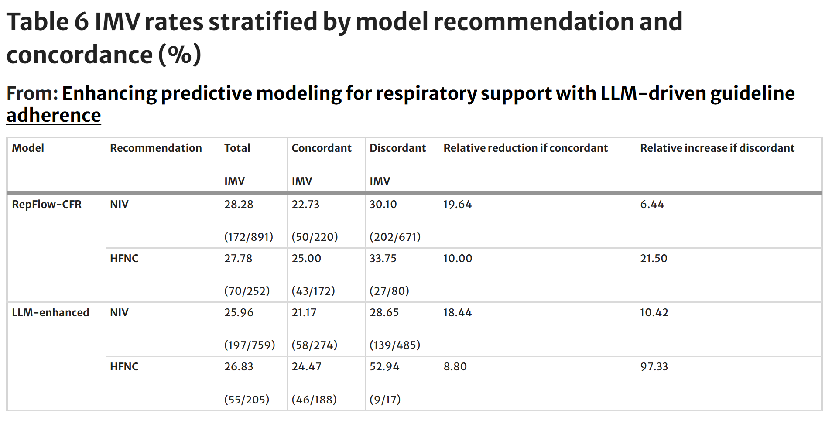
表8多变量校正:LLM-enhanced一致性治疗与更低IMV风险独立相关(HFNC一致组aOR=0.66, p=0.023),证实混杂因素控制后获益依然稳健。
Figure 4. 图表审查与临床有效性验证
20例代表性病例中,95% LLM推荐符合指南,但仅65%获医生完全同意。主要分歧源于:①15%病例存在临床显著性解释错误(如遗漏误吸风险、右心衰禁忌证);②30%缺失关键临床细节。潜在危害评估:低度7例、中度3例、高度1例(严重/死亡2例)。LLM理解力达100%,证据检索与推理正确率95%,但对需床旁实时评估的禁忌证识别不足。
研究结论
本研究成功开发并验证了一个 混合AI决策框架 ,通过LLM驱动的指南约束显著增强了深度反事实模型的临床可解释性与实践对齐度。LLM-enhanced推荐一致性提升与更低IMV及死亡风险独立相关,彰显个体化因果推断与知识型AI融合在重症呼吸支持中的转化潜力。然而,医生-模型分歧揭示LLM在复杂禁忌证识别、临床情境推理方面尚存不足;观察性设计、单中心来源及小样本质控限制证据等级。未来需通过前瞻性RCT确立其安全性与有效性,并构建EHR嵌入式、医生反馈闭环的智能决策支持系统,方能实现可信的床旁落地。
临床有效性未达完全共识的原因分析
1. 指南固有限度:ERS/ATS指南基于RCT人群,对多合并症、右心衰、误吸风险等复杂个体的覆盖不足,导致15% LLM推荐虽符合指南却遭临床否决。
2. 残余混杂风险:一致性分析属观察性数据,虽经多变量校正,仍可能存在未测量混杂(如实时心理状况、血流动力学细微变化),影响因果推断强度。
3. 禁忌证识别缺陷:当前LLM提示工程未强调NIV/HFNC禁忌证(如意识障碍、严重血便、右室衰竭),需床旁实时评估的信息无法从EHR自动获取,导致推荐安全性不足。
4. 医生实践异质性:65%同意率反映真实世界临床决策的个体化与经验性,指南-实践差距客观存在,AI推荐需保留医生最终决策权并建立可修改机制。
5. 小样本质控局限:n=20图表审查难全面捕捉错误模式,阳性预测值与阴性预测值估计不精确,需大样本前瞻性验证队列。
研究的局限性
- LLM错误率:30%病例存在解释不准确或遗漏,其中15%具临床显著性,幻觉与推理错误威胁床旁安全。
- 指南普适性:基于欧美指南,对免疫抑制、COVID-19等特殊人群及新兴疗法(如头盔NIV)的适应性未验证。
- 单中心偏倚:UCSD为学术医学中心,经验性治疗模式、EHR数据结构独特性限制外部推广;U Irvine队列验证尚在进行。
- 观察性设计:无法随机分配"一致性",残余混杂与指示偏倚仍可能影响结局-关联估计。
- 样本量不足:图表审查n=20导致罕见但严重错误检出率低估,需至少200例前瞻性安全监测。
- 实时部署挑战:未评估LLM推理延迟、EHR集成成本、医生应答负荷等工作流可行性问题。
创新点与启发
1. 首个"因果推断+LLM知识层"重症决策框架:突破纯黑箱预测局限,通过LLM将定量ITE估计与定性指南约束耦合,实现可解释个体化推荐。
2. 主动式推荐修正机制:LLM不止于解释,更通过"校验-修正-解释"三步骤主动调整不合理推荐,形成可追溯的临床决策路径,提升透明度。
3. 一致性作为新质量指标:提出"推荐-实践一致率"作为AI辅助决策的替代终点,为观察性研究评估AI影响提供可操作范式。
4. 人机协同决策模式:65%医生同意率揭示AI不应追求取代决策,而应定位为"指南提醒+个体化风险估算"的辅助工具,保留医生最终裁量权。
5. 安全验证方法论:结构化图表审查结合AHRQ伤害分类,为LLM医疗应用的安全性评估建立标准化流程,强调错误危害而非仅准确率。
6. 研究-转化闭环设计:明确分阶段EHR集成、用户中心设计、前瞻性RCT验证路径,为AI从论文到床旁提供可复制的转化蓝图。
文献原文:
